- 在开始之前
- 管理访问权限
- 入门指南
- 集成
- 使用流程应用程序
- 创建应用程序
- 正在加载数据
- Transforming data
- 自定义仪表板
- 发布流程应用程序
- 应用程序模板
- 通知
- 其他资源

Process Mining 用户指南
在数据转换中使用 LLM 函数
查看有关Snowflake AI 和 ML的 Snowflake 官方文档,大致了解 Snowflake 的人工智能和机器学习功能。只有在函数调用中传递的显式数据才会发送到 LLM。
- 数据不会离开Snowflake 环境。
- 数据不会在无法处理的情况下保留,也不会用于训练。
- Snowflake 合同和架构的设计初衷是满足企业数据监管标准。
简介
LLM 函数可用于将非结构化文本处理为分类输出,以在仪表板中进行汇总分析。使用 LLM 函数无需 SQL 中的复杂正则表达式,从而可以更轻松地根据新数据配置和调整转换。
有关使用 LLM 函数的更多信息,请参阅有关Cortex AISQL(包括 LLM 函数)的官方 Snowflake 文档。
在 SQL 中使用 LLM 函数可能会显着影响转换时间。例如,将分类函数应用于 100 万条记录可能会将处理时间增加至少半小时。
数据转换中 LLM 函数的用例示例如下:
- 用于数据分类的
AI_CLASSIFY函数。有关更多信息,请参阅有关AI_CLASSIFY的官方 Snowflake 文档。 ENTITY_SENTIMENT函数,以进行情感分析。有关更多信息,请参阅有关ENTITY_SENTIment的官方 Snowflake 文档。备注:如果您超出 LLM 合理使用限制(不太可能发生),UiPath™ 不会立即施加任何限制,因此客户可以继续不间断地操作。此产品或商业产品如有任何变更,我们将提前告知,以提供流畅、无缝的体验。
分类
本节介绍如何在 Process Mining 上下文中使用AI_CLASSIFY函数,包括示例。
示例:简要流程分析
流程可以由许多不同的活动组成,其中一些活动可能非常相似,因此可以映射到更高级别的类别。此类映射可减少流程变体的数量,并可在更抽象的级别进行分析。
例如,在“采购到付款”流程中,批准事件可以发生在不同的级别,例如“批准采购申请”、“批准 1 级订单”、“经理批准”等。其中每个活动都可以映射到通用的“批准”活动。
另一个例子是“更改”事件,例如“更改价格”、“更改交货日期”或“更改供应商”。将这些活动映射到单个“更改”活动可减少流程中的路径数量,并简化流程图视图。
以下代码块显示了一个 SQL 示例,说明如何应用AI_CLASSIFY函数来定义高级流程。
select
{{ pm_utils.id() }} as "Event_ID",
Purchase_order_item_event_log."Purchase_order_item_ID",
Purchase_order_item_event_log."Event_end",
coalesce(
to_varchar(
AI_CLASSIFY(
Purchase_order_item_event_log."Activity",
['Create', 'Change', 'Approve', 'Complete', 'Cancel']):labels[0]),
'Not mapped') as "High_level_activity"
from {{ ref('Purchase_order_item_event_log') }} as Purchase_order_item_event_log
select
{{ pm_utils.id() }} as "Event_ID",
Purchase_order_item_event_log."Purchase_order_item_ID",
Purchase_order_item_event_log."Event_end",
coalesce(
to_varchar(
AI_CLASSIFY(
Purchase_order_item_event_log."Activity",
['Create', 'Change', 'Approve', 'Complete', 'Cancel']):labels[0]),
'Not mapped') as "High_level_activity"
from {{ ref('Purchase_order_item_event_log') }} as Purchase_order_item_event_log
请提供事件表中的原始“活动”列作为此函数的第一个参数。第二个参数应该是活动将映射到的高级活动的列表。在此示例中,活动映射到“创建”、“更改”、“批准”、“完成”或“取消”。
实施高级流程分析的步骤:
- 在项目中创建一个单独的 SQL 文件,例如
High_level_events.sql,然后向其中添加高级流程 SQL 逻辑。 - 将
High_level_events添加到数据模型并配置关系。在此示例中,高级事件基于Purchase_order_item_ID连接到采购订单项目表。 - 添加一个其他流程,其中采购订单项目作为主要对象,高级事件作为此流程的事件。
- 将更改应用于仪表板时,您可以基于高级流程创建流程图和其他仪表板。
下图显示了一个示例。
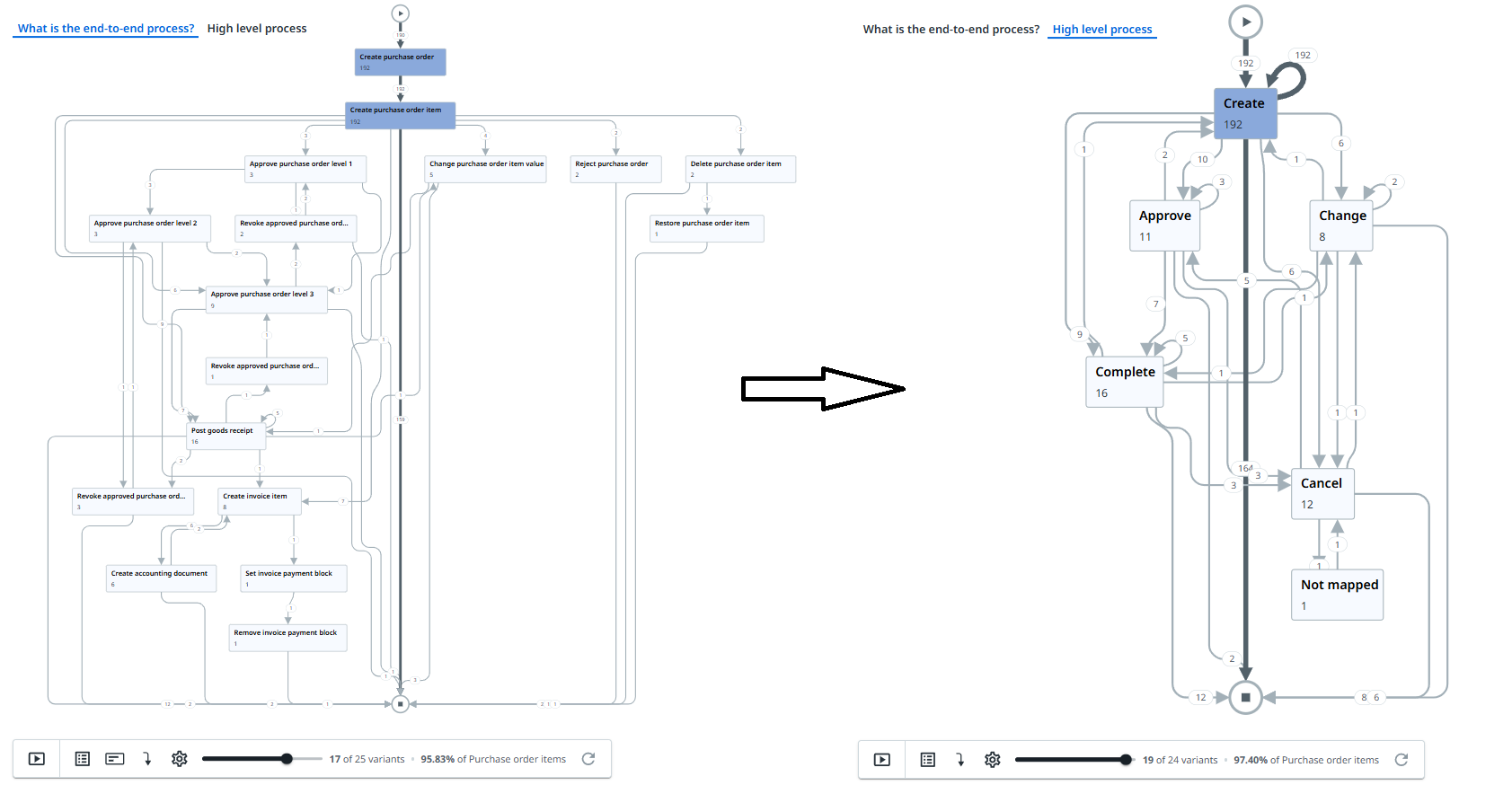
AI_CLASSIFY函数以{ “labels”: [“Create”] }格式返回值。:labels检索值”Create”,而to_varchar()函数删除两边的引号。- 当所有类别都不完全匹配时,
AI_CLASSIFY函数生成的值仍保持为null。要防止从数据集中排除这些记录,请将null值映射到常量(例如"Unmapped"),以指示这些活动未分类。
示例:对客户请求类型进行分类
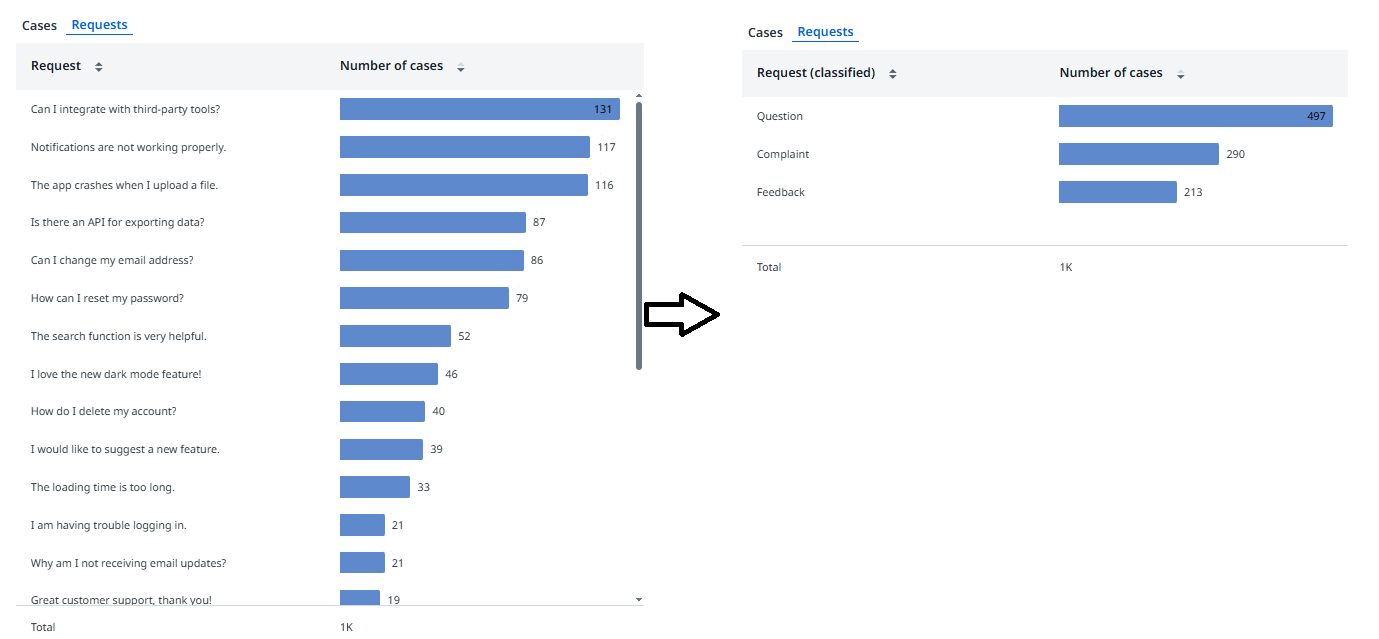
客户请求是非结构化数据的典型示例。每种类型的请求都需要不同的下一个操作。要在仪表板中更有效地分析不同的请求类型,您可以使用 LLM 对其进行分类,而无需用户手动干预。
以下代码块显示了一个 SQL 示例,说明了如何将请求分类为“反馈”、“问题”或“投诉”。
select
Requests_input."Request_ID"
Requests_input."Request",
to_varchar(
AI_CLASSIFY(
Requests_input."Request",
['Feedback', 'Question', 'Complain']):labels[0])
as "Request_classified"
from {{ ref('Requests_input') }} as Requests_input
select
Requests_input."Request_ID"
Requests_input."Request",
to_varchar(
AI_CLASSIFY(
Requests_input."Request",
['Feedback', 'Question', 'Complain']):labels[0])
as "Request_classified"
from {{ ref('Requests_input') }} as Requests_input
对每条记录的值进行分类可能会影响提取性能。要优化处理时间,请考虑筛选应用了AI_CLASSIFY函数的表格,以仅包含与分析相关的记录。
您可以将分类的请求类型添加到应用程序和仪表板中,以启用更多汇总分析。与直接使用原始请求文本相比,这可提供更深入的见解,原始请求文本通常对于每条记录都是唯一的,并且可能会导致生成大量不同的值。
下图显示了一个分类示例。
情感分析
本节介绍如何在 Process Mining 上下文中使用ENTITY_SENTIMENT和SENTIMENT函数,包括示例。
您可以对非结构化文本应用情感分析,以对内容是正面还是负面进行分类。例如,这种类型的分析可用于:
- 分析反馈以改进产品或服务。
- 跟踪一段时间内的情感趋势,以进行决策。
有两类情感分析函数可用。
- 对分类结果使用
ENTITY_SENTIMENT函数(例如,“正面”、“负面”、“中性”、“混合性”或“未知”)。默认情况下,系统会分析输入的文本整体情感。输出以以下格式返回:{ "categories": [ { "name": "overall", "sentiment": "positive" } ] }{ "categories": [ { "name": "overall", "sentiment": "positive" } ] } - 对于数值结果(例如,量表上的情感分数),请使用
SENTIMENT函数。SENTIMENT函数返回一个 -1 到 1 之间的值,表示输入文本中消极或积极的程度。您可以在仪表板指标中使用这些数字情感值来分析不同聚合级别的情感。
有关更多信息,请参阅有关ENTITY_SENTIment的官方 Snowflake 文档。
示例:情感分析用户反馈
以下代码块显示了有关使用情感分析获取用户反馈的 SQL 示例。
select
Feedback_input."Feedback_ID",
Feedback_input."Feedback",
to_varchar(
SNOWFLAKE.CORTEX.ENTITY_SENTIMENT(
Feedback_input."Feedback"):categories[0]:sentiment)
as "Sentiment_category",
SNOWFLAKE.CORTEX.SENTIMENT(
Feedback_input."Feedback")
as "Sentiment_value"
from {{ ref('Feedback_input') }} as Feedback_input
select
Feedback_input."Feedback_ID",
Feedback_input."Feedback",
to_varchar(
SNOWFLAKE.CORTEX.ENTITY_SENTIMENT(
Feedback_input."Feedback"):categories[0]:sentiment)
as "Sentiment_category",
SNOWFLAKE.CORTEX.SENTIMENT(
Feedback_input."Feedback")
as "Sentiment_value"
from {{ ref('Feedback_input') }} as Feedback_input
默认情况下,仅确定整体情感。如果要指定要获取其情感的特定主题(例如“价格”或“支持”),则可以将类别作为第二个参数添加到ENTITY_SENTIMENT函数。输出将是每个指定类别的情感值。
要提取正确的值,您必须调整 SQL 逻辑。不要引用category[0] (它仅选择第一个类别),而是修改查询以选择感兴趣的特定类别的情感值。
下图显示了用户反馈情感分析的示例结果。
