- Overview
- Document Understanding Process
- Quickstart tutorials
- Framework components
- ML packages
- Overview
- Document Understanding - ML package
- DocumentClassifier - ML package
- ML packages with OCR capabilities
- 1040 - ML package
- 1040 Schedule C - ML package
- 1040 Schedule D - ML package
- 1040 Schedule E - ML package
- 1040x - ML package
- 3949a - ML package
- 4506T - ML package
- 709 - ML package
- 941x - ML package
- 9465 - ML package
- 990 - ML Package - Preview
- ACORD125 - ML package
- ACORD126 - ML package
- ACORD131 - ML package
- ACORD140 - ML package
- ACORD25 - ML package
- Bank Statements - ML package
- Bills Of Lading - ML package
- Certificate of Incorporation - ML package
- Certificate of Origin - ML package
- Checks - ML package
- Children Product Certificate - ML package
- CMS 1500 - ML package
- EU Declaration of Conformity - ML package
- Financial Statements - ML package
- FM1003 - ML package
- I9 - ML package
- ID Cards - ML package
- Invoices - ML package
- Invoices China - ML package
- Invoices Hebrew - ML package
- Invoices India - ML package
- Invoices Japan - ML package
- Invoices Shipping - ML package
- Packing Lists - ML package
- Passports - ML package
- Payslips - ML package
- Purchase Orders - ML package
- Receipts - ML package
- Remittance Advices - ML package
- UB04 - ML package
- Utility Bills - ML package
- Vehicle Titles - ML package
- W2 - ML package
- W9 - ML package
- Other Out-of-the-box ML Packages
- Public Endpoints
- Hardware requirements
- Pipelines
- Document Manager
- OCR services
- Supported languages
- Deep Learning
- Insights dashboards
- Document Understanding deployed in Automation Suite
- Document Understanding deployed in AI Center standalone
- Licensing
- Activities
- UiPath.Abbyy.Activities
- UiPath.AbbyyEmbedded.Activities
- UiPath.DocumentProcessing.Contracts
- UiPath.DocumentUnderstanding.ML.Activities
- UiPath.DocumentUnderstanding.OCR.LocalServer.Activities
- UiPath.IntelligentOCR.Activities
- UiPath.OCR.Activities
- UiPath.OCR.Contracts
- UiPath.OmniPage.Activities
- UiPath.PDF.Activities

Document Understanding user guide
Full pipelines
A full pipeline runs a training pipeline and an evaluation pipeline together.
Minimal dataset size For successfully running a Training pipeline, we strongly recommend at least 25 documents and at least 10 samples from each labeled field in your dataset. Otherwise, the pipeline throws the following error: Dataset Creation Failed. **
Training on GPU vs CPU**
- For larger datasets, you need to train using GPU. Moreover, using a GPU (AI Robot Pro) for training is at least 10 times faster than using a CPU (AI Robot).
- Training on CPU is only supported for datasets up to 5000 pages in size for ML Packages v21.10.x and up to 1000 pages for other versions of ML Packages.
- CPU training was limited to 500 pages before 2021.10, it went up to 5000 pages for 2021.10 and with 2022.4 it came back down to 1000 pages max.
Train and evaluate a model at the same time
Configure the training pipeline as follows:
-
In the Pipeline type field, select Full Pipeline run.
-
In the Choose package field, select the package you want to train and evaluate.
-
In the Choose package major version field, select a major version for your package.
-
In the Choose package minor version field, select a minor version for your package. It is strongly recommended to always use minor version 0 (zero).
-
In the Choose input dataset field, select a representative training dataset.
-
In the Choose evaluation dataset field, select a representative evaluation dataset.
-
In the Enter parameters section, enter any environment variables defined, and used by your pipeline, if any. For most use cases, no parameter needs to be specified; the model is using advanced techniques to find a performant configuration. However, here are some environment variables you could use:
-
model.epochswhich customizes the number of epochs for the Training Pipeline (the default value is 100). -
Select whether to train the pipeline on GPU or on CPU. The Enable GPU slider is disabled by default, in which case the pipeline is trained on CPU. Using a GPU (AI Robot Pro) for training is at least 10 times faster than using a CPU (AI Robot). Moreover, training on CPU is supported for datasets up to 1000 images in size only. For larger datasets, you need to train using GPU.
-
Select one of the options when the pipeline should run: Run now, Time based or Recurring. In case you are using the
auto_retrainingvariable, select Recurring.
After you configure all the fields, select Create. The pipeline is created.
Artifacts
For an Evaluation Pipeline, the Outputs pane also includes an artifacts / eval_metrics folder which contains two files:
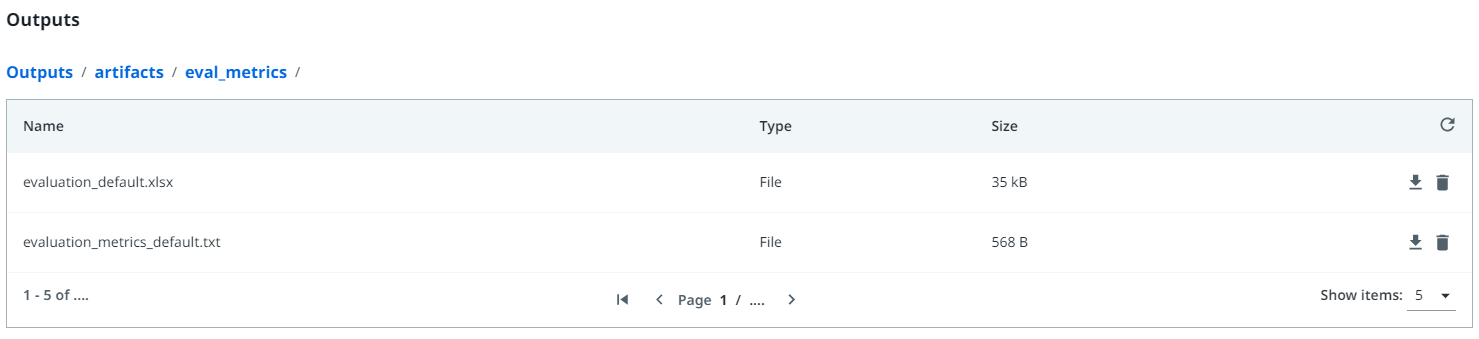
-
evaluation_default.xlsxis an Excel spreadsheet with a side-by-side comparison of ground truth versus predicted value for each field predicted by the model, as well as a per-document accuracy metric, in order of increasing accuracy. Hence, the most inaccurate documents are presented at the top to facilitate diagnosis and troubleshooting. -
evaluation_metrics_default.txtcontains the F1 scores of the fields which were predicted.For line items, a global score is obtained for all columns taken together.