- Introduction
- Setting up your account
- Balance
- Clusters
- Concept drift
- Coverage
- Datasets
- General fields
- Labels (predictions, confidence levels, label hierarchy, and label sentiment)
- Models
- Streams
- Model Rating
- Projects
- Precision
- Recall
- Annotated and unannotated messages
- Extraction Fields
- Sources
- Taxonomies
- Training
- True and false positive and negative predictions
- Validation
- Messages
- Access control and administration
- Manage sources and datasets
- Understanding the data structure and permissions
- Creating or deleting a data source in the GUI
- Preparing data for .CSV upload
- Uploading a CSV file into a source
- Creating a dataset
- Multilingual sources and datasets
- Enabling sentiment on a dataset
- Amending dataset settings
- Deleting a message
- Deleting a dataset
- Exporting a dataset
- Using Exchange integrations
- Model training and maintenance
- Understanding labels, general fields, and metadata
- Label hierarchy and best practices
- Comparing analytics and automation use cases
- Turning your objectives into labels
- Overview of the model training process
- Generative Annotation
- Dastaset status
- Model training and annotating best practice
- Training with label sentiment analysis enabled
- Understanding data requirements
- Train
- Introduction to Refine
- Precision and recall explained
- Precision and Recall
- How validation works
- Understanding and improving model performance
- Reasons for label low average precision
- Training using Check label and Missed label
- Training using Teach label (Refine)
- Training using Search (Refine)
- Understanding and increasing coverage
- Improving Balance and using Rebalance
- When to stop training your model
- Using general fields
- Generative extraction
- Using analytics and monitoring
- Automations and Communications Mining™
- Developer
- Uploading data
- Downloading data
- Exchange Integration with Azure service user
- Exchange Integration with Azure Application Authentication
- Exchange Integration with Azure Application Authentication and Graph
- Migration Guide: Exchange Web Services (EWS) to Microsoft Graph API
- Fetching data for Tableau with Python
- Elasticsearch integration
- General field extraction
- Self-hosted Exchange integration
- UiPath® Automation Framework
- UiPath® official activities
- How machines learn to understand words: a guide to embeddings in NLP
- Prompt-based learning with Transformers
- Efficient Transformers II: knowledge distillation & fine-tuning
- Efficient Transformers I: attention mechanisms
- Deep hierarchical unsupervised intent modelling: getting value without training data
- Fixing annotating bias with Communications Mining™
- Active learning: better ML models in less time
- It's all in the numbers - assessing model performance with metrics
- Why model validation is important
- Comparing Communications Mining™ and Google AutoML for conversational data intelligence
- Licensing
- FAQs and more

Communications Mining user guide
Elasticsearch integration
Communications Mining™ offers a rich set of built-in analytics tools. However, sometimes it is necessary to join the predictions from Communications Mining with data that can't be uploaded as part of Communications Mining comments. In these cases a common solution is to index the Communications Mining predictions and any additional data into Elasticsearch and use a tool like Kibana to drive analytics. This tutorial describes how to import Communications Mining data into Elasticsearch and visualize it in Kibana.
The data used in the examples throughout this tutorial is generated dummy emails from the insurance domain.
Storing data in Elasticsearch
First, let's define the data that we want to import into Elasticsearch. Communications Mining™ API provides the comment text, comment metadata, predicted labels and predicted general fields in a nested JSON object. The following is an example of a raw comment provided by the Communications Mining API.
You may notice different metadata fields depending on how your data was ingested into Communications Mining. To learn more about comment object fields, check Comments.
{
"comment": {
"id": "c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"uid": "49ba2c56a945386c.c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"timestamp": "2021-03-29T08:36:25.607Z",
"messages": [
{
"body": {
"text": "The policyholder has changed their address to the new address: 19 Essex Gardens, SW17 2UL"
},
"subject": {
"text": "Change of address - Policy SFG48807871"
},
"from": "[email protected]",
"to": ["[email protected]"],
"sent_at": "2021-03-29T08:36:25.607Z"
}
]
// (... more properties ...)
},
"labels": [
{
"name": ["Admin"],
"probability": 0.9995054006576538
},
{
"name": ["Admin", "Change of address"],
"probability": 0.9995054006576538
}
],
"entities": [
{
"name": "address-line-1",
"formatted_value": "19 Essex Gardens",
"span": {
"content_part": "body",
"message_index": 0,
"char_start": 63,
"char_end": 79,
"utf16_byte_start": 126,
"utf16_byte_end": 158
}
},
{
"name": "post-code",
"formatted_value": "SW17 2UL",
"span": {
"content_part": "body",
"message_index": 0,
"char_start": 81,
"char_end": 89,
"utf16_byte_start": 162,
"utf16_byte_end": 178
}
},
{
"name": "policy-number",
"formatted_value": "SFG48807871",
"span": {
"content_part": "subject",
"message_index": 0,
"char_start": 27,
"char_end": 38,
"utf16_byte_start": 54,
"utf16_byte_end": 76
}
}
]
}
{
"comment": {
"id": "c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"uid": "49ba2c56a945386c.c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"timestamp": "2021-03-29T08:36:25.607Z",
"messages": [
{
"body": {
"text": "The policyholder has changed their address to the new address: 19 Essex Gardens, SW17 2UL"
},
"subject": {
"text": "Change of address - Policy SFG48807871"
},
"from": "[email protected]",
"to": ["[email protected]"],
"sent_at": "2021-03-29T08:36:25.607Z"
}
]
// (... more properties ...)
},
"labels": [
{
"name": ["Admin"],
"probability": 0.9995054006576538
},
{
"name": ["Admin", "Change of address"],
"probability": 0.9995054006576538
}
],
"entities": [
{
"name": "address-line-1",
"formatted_value": "19 Essex Gardens",
"span": {
"content_part": "body",
"message_index": 0,
"char_start": 63,
"char_end": 79,
"utf16_byte_start": 126,
"utf16_byte_end": 158
}
},
{
"name": "post-code",
"formatted_value": "SW17 2UL",
"span": {
"content_part": "body",
"message_index": 0,
"char_start": 81,
"char_end": 89,
"utf16_byte_start": 162,
"utf16_byte_end": 178
}
},
{
"name": "policy-number",
"formatted_value": "SFG48807871",
"span": {
"content_part": "subject",
"message_index": 0,
"char_start": 27,
"char_end": 38,
"utf16_byte_start": 54,
"utf16_byte_end": 76
}
}
]
}
The schema of the raw comments returned by the Communications Mining API is inconvenient for filtering and querying this data in Elasticsearch, so you should change the schema before ingesting the data into Elasticsearch. The following is an example flattened schema you can use. You should add all fields that you need for your use-case.
{
"id": "c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"uid": "49ba2c56a945386c.c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"timestamp": "2021-03-29T08:36:25.607Z",
"subject": "Change of address - Policy SFG48807871",
"body": "The policyholder has changed their address to the new address: 19 Essex Gardens, SW17 2UL",
// (... more fields ...)
"labels": ["Admin", "Admin > Change of address"],
"entities": {
"policy_number": ["SFG48807871"],
"address-line-1": ["19 Essex Gardens"],
"post-code": ["SW17 2UL"]
}
}
{
"id": "c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"uid": "49ba2c56a945386c.c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"timestamp": "2021-03-29T08:36:25.607Z",
"subject": "Change of address - Policy SFG48807871",
"body": "The policyholder has changed their address to the new address: 19 Essex Gardens, SW17 2UL",
// (... more fields ...)
"labels": ["Admin", "Admin > Change of address"],
"entities": {
"policy_number": ["SFG48807871"],
"address-line-1": ["19 Essex Gardens"],
"post-code": ["SW17 2UL"]
}
}
A comment can have zero, one, or multiple labels, so the labels field needs to be an array. Additionally, if one or more general field types have been configured for the dataset, a comment will have zero, one, or more general fields of each general field type. The hierarchical label names in the raw API response are themselves arrays (["Admin", "Change of address"]), and should be converted to strings ("Admin > Change of address").
Fetching Data
In order to fetch the data, we recommend using the. For an overview of all available data download methods, check Downloading data. When creating a Stream, you should set the thresholds for each label so that labels with confidence scores below the threshold are discarded. This is easiest to do from the Communications Mining™ UI by going to the "Streams" page of a dataset. Having used the confidence scores to determine whether a label applies, you can then import just the label names into Elasticsearch. For a discussion on when we recommend dropping or keeping label confidence scores, check Labels for Analytics.
General fields do not have confidence scores, so no special handling is required.
Model change management When you create a Stream, you specify a model version, which is used to provide predictions when fetching comments from the Stream. Even as you continue to train new model versions in the platform, your Stream will use the model version you specified, providing you with deterministic results.
To upgrade to a new model version, you must create a new Stream that uses that model version, then update your code to use the new Stream. For this reason, we recommend that you make the Stream name configurable in your code.
To make sure that analytics that use predictions stay consistent, you should re-ingest predictions for historical data using the updated model version. You can do that by the Stream to the timestamp before your oldest comment, and re-ingesting the data from the start.
Visualizing Data in Kibana
Once you indexed the data in Elasticsearch, you can start building visualizations. This section provides simple examples for a number of common visualization tools in Kibana.
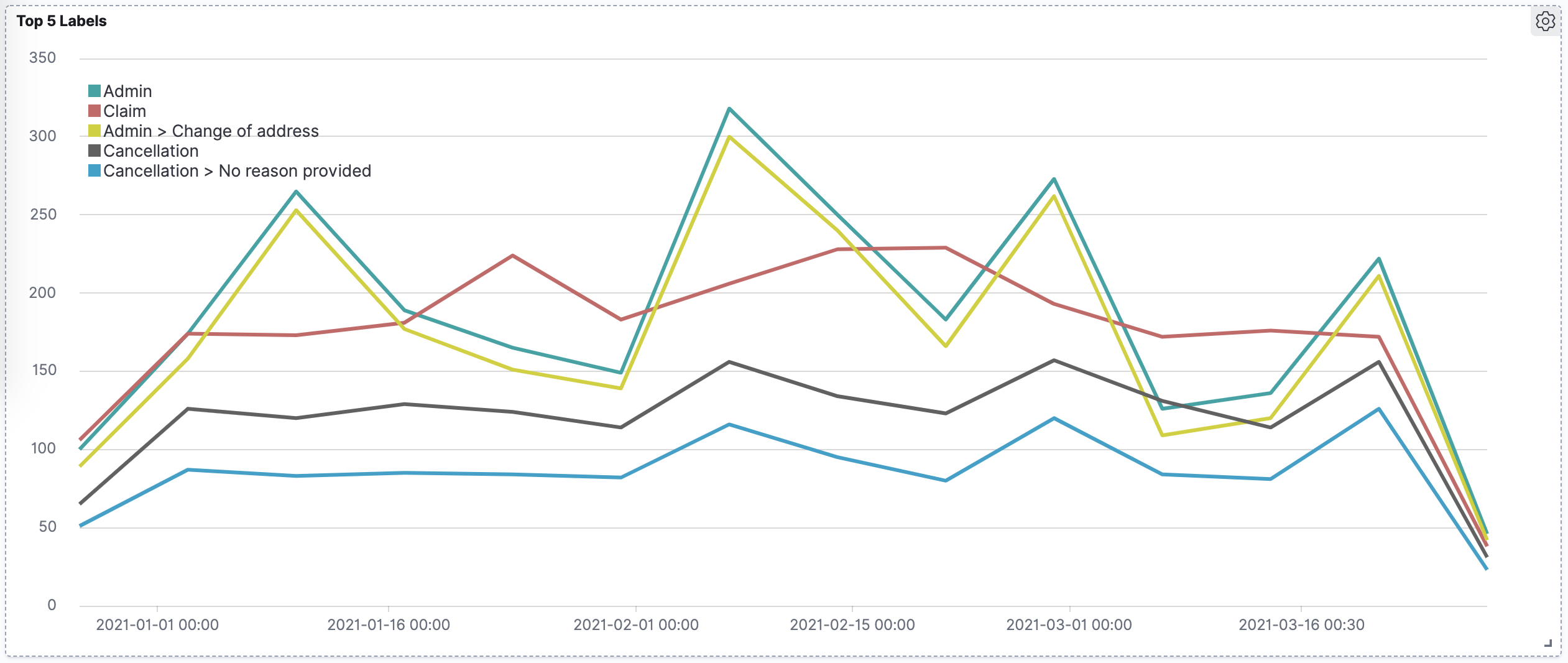
Timelion
You can use the following expression to produce a plot of top 5 most common labels over time.
This shows both top-level category and subcategory labels.
.es(index=example-data,split=labels:5,timefield=@timestamp)
.label("$1", "^.* > labels:(.+) > .*")
.es(index=example-data,split=labels:5,timefield=@timestamp)
.label("$1", "^.* > labels:(.+) > .*")
Figure 1. Top 5 labels in a dataset plotted over time.
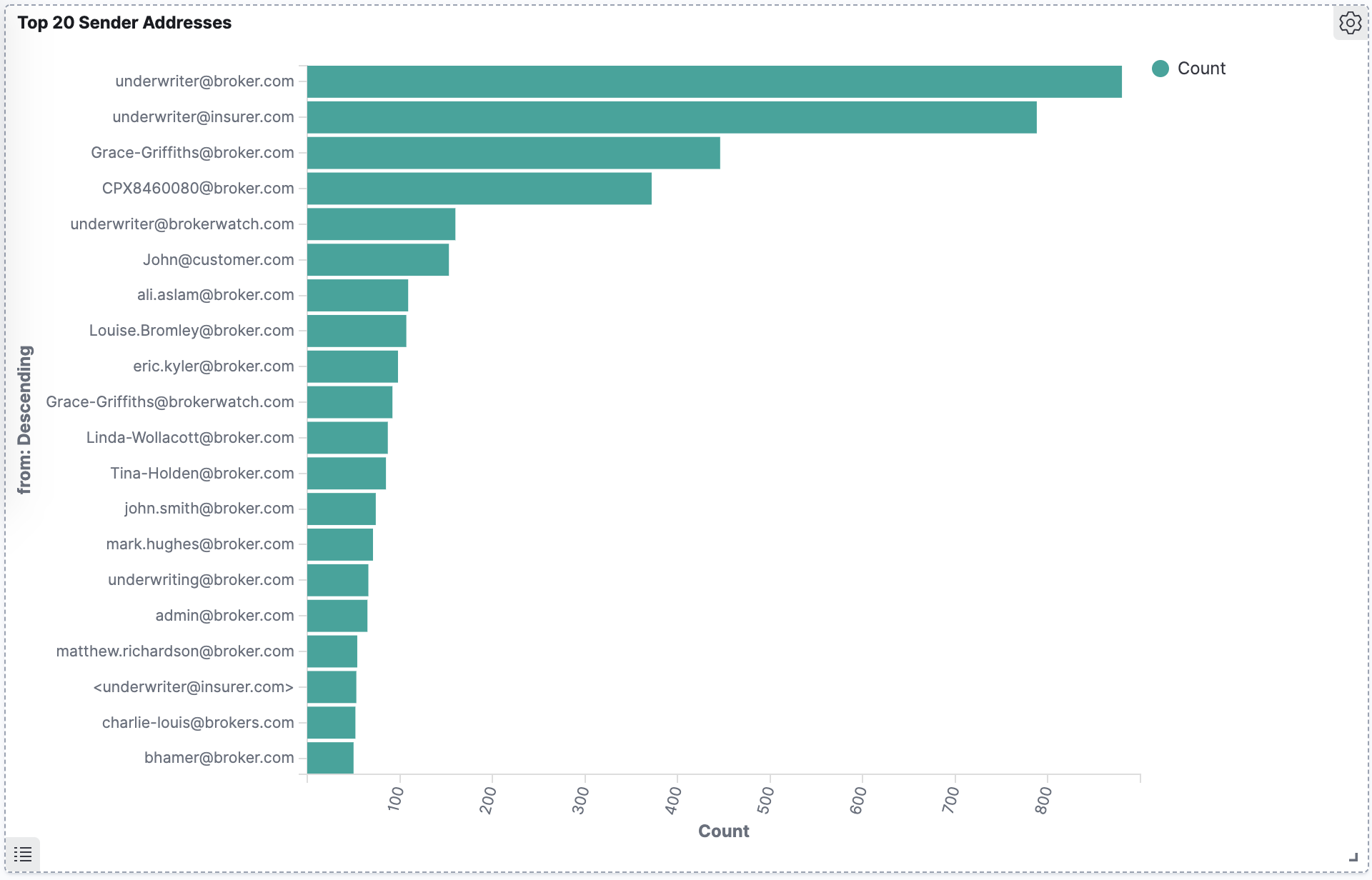
Bar Chart
This bar chart shows the top 20 sender email addresses in the dataset. Sender and recipient email addresses are part of comment metadata in email-based datasets.
Figure 2. Top 20 sender email addresses.
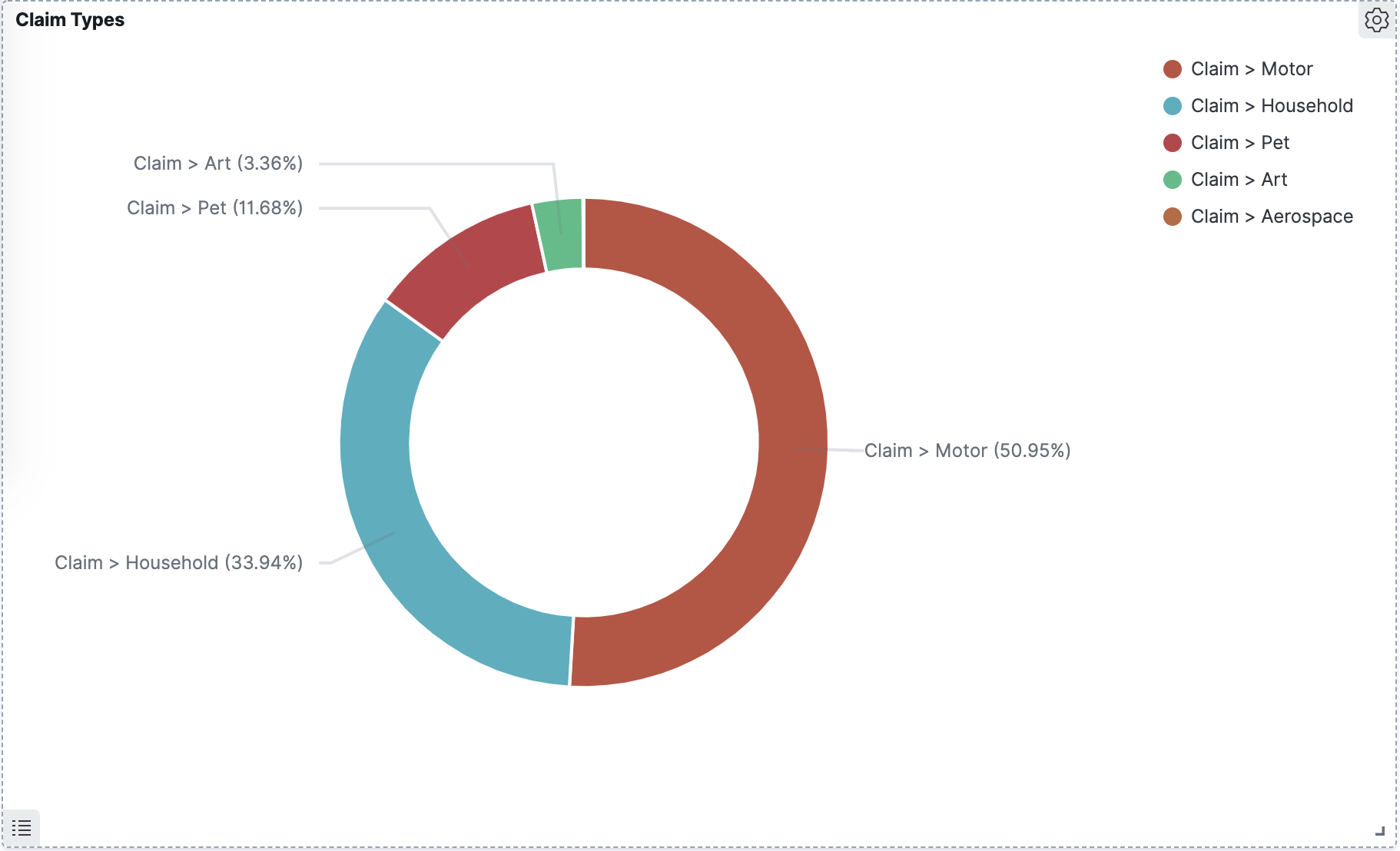
Pie Chart
This pie chart shows subcategory labels under the top-level "Claim" label. The label categories are defined by the user training the model.
Figure 3. Subcategories of the Claim label.