- Getting started
- Setup and configuration
- Unassisted Task Mining
- Additional resources
- Unassisted Task Mining analysis guide
- Troubleshooting
- Glossary
- FAQs
Introduction
This guide serves as an introduction to working with Unassisted Task Mining analysis results after a project is created, recording of actions is completed, and an analysis is run. It is intended for Business Analysts, Project Administrators, and others who want to learn how to interpret Unassisted Task Mining results and identify tasks with the potential for optimization. This guide also provides guidance on how to handle unexpected results and noise from the analysis.
To generate results, the AI algorithm looks for occurrences of the same sequence of steps within the recorded data. It works without any context and might therefore present tasks candidates that do not fully capture real-life tasks from the beginning to the end.
Sometimes the analysis results may include tasks and steps that are irrelevant from a business perspective. This is considered noise. To identify automation candidates, it is important for the reviewer to differentiate between high-quality tasks and noise.
Different types of Task Mining results
The task candidates identified by the AI algorithm may align with real-life tasks, but they may also differ from what is expected. Not all task candidates are suitable for automation, and the reviewer needs to be familiar with the different types of results they might encounter. The identified task candidates may:
- Not show the expected tasks
- Show unexpected tasks
- Split one real-life task into multiple tasks
- Partially capture a task without the real start and end
- Not show a realistic task
1. Results do not show expected tasks
Unassisted Task Mining applies an algorithm to identify task candidates, which may be good candidates for automation or process optimization. The AI algorithm is not guaranteed to detect everything, and it may detect a partial process or even a larger process than expected. By following the steps provided in this document, the reviewer can determine whether the identified task candidates are suitable for automation. Since Unassisted Task Mining is not guaranteed to detect known tasks or to pick out every variation or iteration, it shouldn't be used purely for monitoring known tasks.
2. Results show unexpected tasks
Unassisted Task Mining identifies task candidates which are then ranked by how likely they are to be better automation opportunities. Some results may not be representative of any actual real-life task, but the reviewer can still identify them as good automation candidates based on the steps presented in this document.
3. Results split real tasks into multiple Task Mining task candidates
The Unassisted Task Mining algorithm looks for the most frequently occurring and consistent sequence of steps. Depending on how consistent users executed the task, a real-life task may be split up into multiple task candidates in the results. The end of one task candidate may be the start of the next one. The task candidate might still be suitable for automation or process improvement actions. In that case, we recommend combining these subtasks in the Process Definition Document (PDD) by exporting all relevant traces to Task Capture and combining them into one document. Combining the subtasks by doing a recompute in Task Mining may not produce optimal results if the subtasks share the start and end steps.
4. Results partially capture a task without the real start or end
The AI algorithm identifies the most consistent sequences of steps as task candidates. Depending on the variability of users executing the task, the middle of a task might be more consistent than the start and/or the end causing the algorithm to detect this sub-task as a candidate instead of the full end-to-end task.
This is likely to occur when the start and/or end of a task involves highly multi-functional applications such as Outlook, Excel, etc. These applications are likely used during multiple tasks, and it is difficult for the algorithm to distinguish specific occurrences of them as the start or end of a task candidate. In this case, we recommend focusing on the bulk of the tasks, not covering 100% of all the clicks that a user does. If the task is a suitable candidate for automation regardless, the missing start, and end can be added when building the automation.
5. Results show an unrealistic task
The discovered task candidate may not look realistic or isn't a recognizable task. If a task candidate doesn't make sense from a business perspective, it's likely noise and can be discarded.
Prioritizing task candidates for analysis
Depending on the recorded data, the Task Mining algorithm might identify many task candidates. Therefore, it's important for the reviewer to prioritize which candidates to analyze first to not waste time on task candidates which aren't likely to be suitable automation candidates. The Discovery Results page and its KPIs provide input for this prioritization.
The task candidates in the Discovery results are ordered by how likely they are to be a suitable automation candidate. The higher the task candidate is on the list, the more likely it is to be a good automation candidate. The task candidate with the name 'Task 0' has been identified as best automation candidate by the Unassisted Task Mining algorithm, considering various factors, including repeatability and complexity. However, this ranking does not indicate the overall quality of the Task Mining results, but relatively 'Task 0' is more likely to be better than 'Task 10'.
The reviewer can also alter the standard sorting by clicking on the column headers. The three ordering options available for the Task name column are highest to lowest automation potential, lowest to highest automation potential and alphabetically based on the task name.
Use the Significant tasks only button to filter to only show tasks that have at least 5 actions, 3 steps and 30 seconds execution time. This should reduce noise from the results.
![]()
Focus on larger task groups. Task candidates that are grouped together are often more meaningful task candidates. Check for the best task representative within a task group. When analyzing a task candidate that is the representative of the group, it can occur that this task candidate has a high automation potential, but the end-to-end task is not entirely correct. In that case, we recommend checking the alternative task candidates of the group for a better representative. Once the reviewer has found a better representative, they can select it and mark it as a new representative for this task group.
Within a task group, focus on the higher-ranked tasks. Generally, the better-ranked task alternatives inside a group are of higher quality. Task alternatives ranked past 10 or 20 are usually lower quality.
During the analysis of the alternative task candidates, it might become clear that some of them relate to a different task than the representative one. In this case, the reviewer can create a new task group based on these alternative tasks.
Investigate the metrics of the different task candidates. Each task candidate displays different metrics like the total time spent by the users on this task, number of users who have performed this task, number of steps in the most representative task etc. Consider these metrics in your analysis and apply your own criteria based on the business context of your Task Mining project for example we can see that Task 7 has a much lower Total time, number of Traces and Steps compared to Task 1 and Task Group New. This might indicate that Task 7 has a lower automation potential. However, please note there are no overall guidelines regarding large or small Total time that hold across all Task Mining studies. These metrics should always be interpreted in the business context of the specific Task Mining project.
Make use of the bookmark and rename functionality. When prioritizing the different task candidates for deeper analysis, it is important to keep an overview of what has been prioritized or even already analyzed. Bookmarking and renaming task candidates can help to structure the analysis.
Analyzing individual task candidates
After the Reviewer has prioritized the different task candidates, your analysis can begin. To guide the reviewer, the following section first provides some insights to keep in mind during the analysis and afterward provides a step-by-step guide on how to navigate through the analysis view.
Keep in mind during the analysis
The steps are based on screens. The task candidate and its steps are displayed at the level of a unique user interface/screen and do not represent individual click or type actions. Multiple clicks or type actions that occur on the same screen will usually be grouped by the Task Mining algorithm. Therefore, the graph does not show each individual click or type action.
A task candidate needs at least two steps (screens) to be identified as such. For the Task Mining algorithm to identify a task candidate, it needs to consist of a clear start and end step. Therefore, a task that is only performed on one screen will not be identified as a task candidate.
Steps are the same throughout the different task candidates. Steps are not bound to one specific task candidate. A step that occurs in one task candidate can also occur in another one. This means that actions like renaming a step will have an effect throughout the entire project.
The PII masking algorithm may incorrectly mark or not mark something as PII. The PII module is an AI algorithm that can detect PII. It might occur that the algorithm makes a mistake and some PII may not be masked or text which is not PII may be masked. These mistakes depend on the detected text on the screen as well as the context of the words themselves. If the text is not captured by the OCR or is partially cut off, it might not be masked. Additionally, if the other words on the screen are different, it is possible for the same text to be identified as PII in one screen and not PII in another.
If a task candidate does not make visual sense when examining traces, it is likely not a high-quality task candidate. The algorithm can detect noisy and irrelevant task candidates, especially at lower ranks in the task ranking. These task candidates might be very short or very long, and extremely variable. Once this becomes clear after examining a few traces, you should not waste your time trying to interpret them.
Look for the bulk of the process (80/20 rule). The task candidates may not align fully with the expected real-life tasks but only partially cover sub-parts of it. As already mentioned above, depending on the variability of users executing the task, certain steps of a task might be more consistent than others causing the algorithm to only detect certain steps of the task as candidate instead of the full end-to-end task.
The task candidate might still be suitable for automation regardless of missing steps. These can be added when building the automation.
Scroll through the results. The traces of a task candidate and the screenshots for the steps are sorted chronologically. Therefore, it is recommended to scroll through the lists to review the results at multiple points.
Step-by-step analysis
To closely analyze the prioritized task candidates, follow the steps below. This will help in differentiating between automation candidates and noisy tasks
- Analyze the start and end step of the task candidate to determine their quality
- Click on the step, this will show the screenshots on the right side of the screen.
- Examine the screenshots of the start and end step of the task candidate to understand what is happening. A high-quality step is consistent in the application used and the work that is performed. If the screenshots of the start or end step show many different screens and actions, its traces will be highly inconsistent. This is an indication that the task candidate is probably not a good candidate for automation.
- The screenshots are ordered chronologically, so it is good practice to review the screenshots in the beginning, middle and end of the list.
- Rename the steps, this helps you keep an overview of which steps have been reviewed.
- Open and review the key steps in the process
-
Find key steps by adjusting the step occurrence filter at the bottom. Try to balance the variance and understandability. Pushing the slider further to the left generally reduces complexity at the cost of completeness. To make it easier, you should move the slider to the left to have just 2-3 steps in addition to the start and end step.
-
Filter for high-quality traces. The filter for most frequent path traces may provide the most useful trace, therefore it is recommended to analyze these traces first. Apply the filter to only see traces follow this most frequent path. This filter is available in the filter panel
-
Review the screenshots as described in the analysis of the start and end steps. Some inconsistent and noisy steps are acceptable, but ideally, a task candidate with high automation potential will have at least a few high-quality steps in the middle of the graph that are part of most traces.
-
Rename the steps. This helps you keep an overview of which steps have been reviewed.
-
- Review traces
- Traces are ordered chronologically. We recommend reviewing traces at the beginning of the list, in the middle, and toward the end.
- A high-quality task candidate will contain many traces that look similar. Look for the following indicators:
- Traces have similar steps in the middle of the trace.
- Traces make sense from a business perspective.
- Check the screenshots to see whether trace information on the item that is worked on is the same within each trace, but different between traces (e.g., issue ID, customer name, invoice number etc.). Make sure you are analyzing this on the right level, as an invoice number may appear in multiple traces, but each trace covers a different line of the invoice.
- If you determine during the analysis of the traces that task candidate is of poor quality, it is recommended to not focus on them and move on to the next task candidate in your priority list.
- Filter out the low-quality traces. Even a high-quality task candidate will contain some low-quality traces, where the algorithm made a mistake. These traces will often be much longer or much shorter than others and include noise or irrelevant actions. Remove them by applying the filters located next to the search bar. Adjust the filters based on the histograms to filter out traces.
Often the high-quality traces will form a larger bump within the histogram. If there are small peaks on the edges, far away from the main bulk of the histogram, we recommend using the sliders to remove those and see if that improves the task graph and traces. Traces with very low or very high step and action counts are likely not suitable task candidates.
If you want to return to a specific filter setting in the future, use the save views functionality.
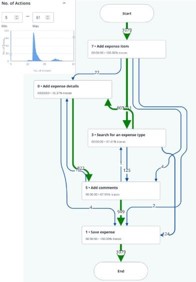
- If your desired step is not showing in the chart, go into a specific trace. Set occurrence to 100% and remove the ‘Show only key steps’ filter. Then go back to all the traces, and filter for the desired step.
- Recompute steps
- Once you have selected high-quality traces and identified the key activities, we recommend recomputing. Only select the key steps which should be included in the task candidate, leave out irrelevant or noisy steps and define the correct order of steps.
Note that this will also further reduce the steps that you have available for the next recompute. Therefore, narrowing down task candidates might become more difficult. The recompute option also includes a version history which enables you to reload a previous version of a task candidate if you are not satisfied with the outcome of a recompute.
Rename steps
Renaming steps serves two purposes. First, it makes the steps more interpretable. Second, it allows you to distinguish between high quality and noise. Since steps can occur in multiple task candidates, renaming them will save you the trouble of reviewing them again in the next task candidate. Some best practices:
- High-quality step: rename to Application name + verb + noun. It is not possible to filter for applications, but you can filter for step names. When there are multiple applications used for the task, this makes the analysis easier.
- Noise steps: rename to noise.