- Información general
- Creación de modelos
- Validación del modelo
- Información general
- Evaluar el rendimiento del modelo
- Recopilar estadísticas de validación
- Iteración en la taxonomía
- Implementación del modelo
- API
- Preguntas frecuentes

Guía del usuario de Documentos complejos y no estructurados
Evaluar el rendimiento del modelo
Puedes evaluar el rendimiento del modelo en las siguientes ubicaciones:
- La pestaña Crear, que muestra la puntuación general del proyecto, así como la tasa de error para cada documento.
- La pestaña Medir, que muestra el rendimiento a nivel de grupo de campos y de campo.
Evaluación del rendimiento del modelo en Crear
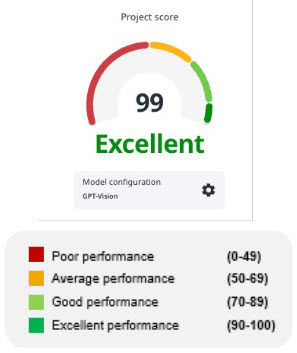
Puedes ver una clasificación general en la puntuación del proyecto en la pestaña Crear.
- Los modelos saludables tienen una puntuación del proyecto de Buena o Excelente y no presentan advertencias sobre el rendimiento en el campo.
- La puntuación del proyecto se calcula en función de la puntuación F1 promedio en todos los campos.
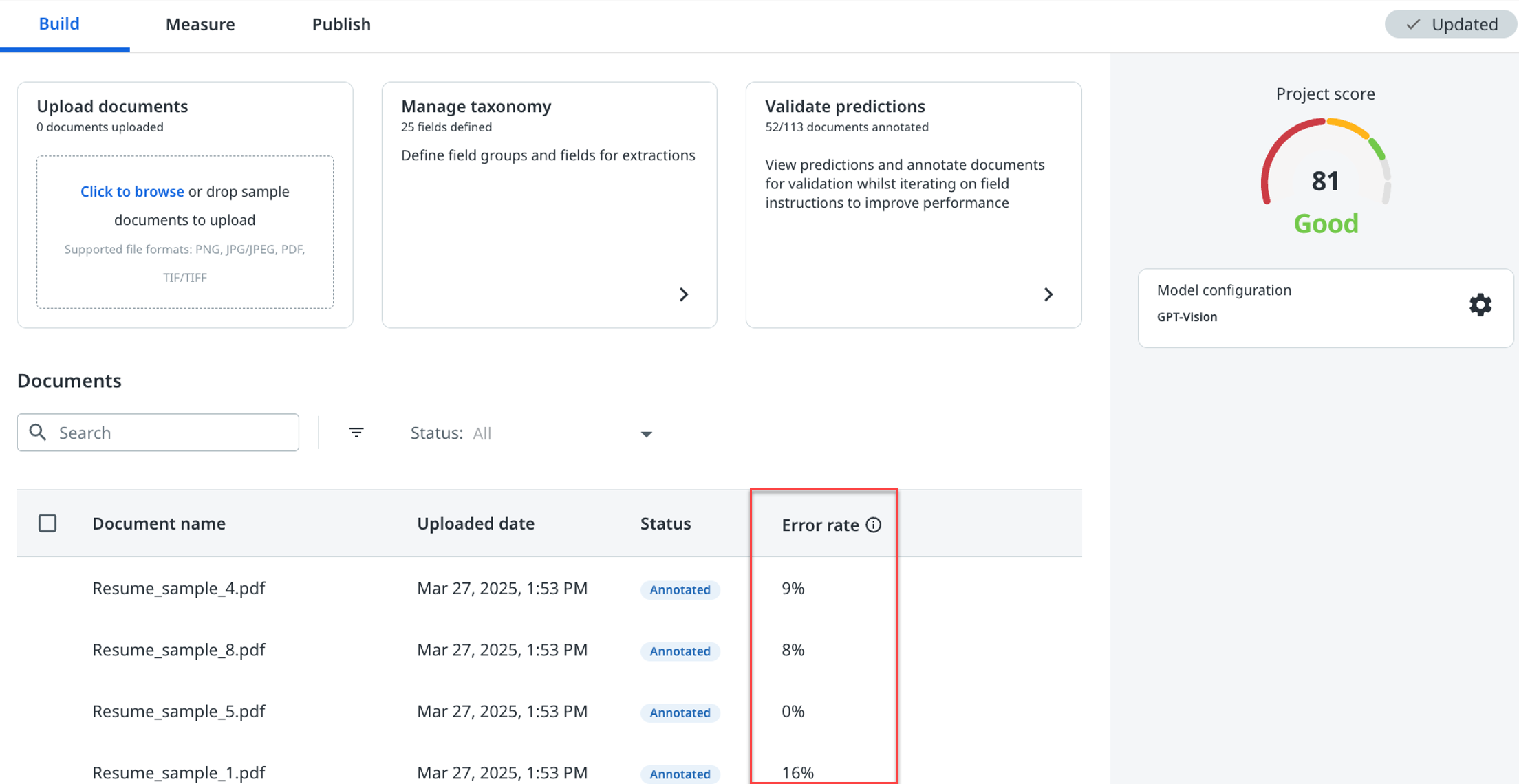
Además, puedes ver la tasa de error para cada documento en la columna Tasa de error de la sección Documentos en Crear.
Las tasas de error solo están disponibles para los documentos anotados e indican el número de errores que cometió el modelo en cada documento, es decir, la diferencia entre las predicciones del modelo y las anotaciones del usuario.
Evaluar el rendimiento del modelo en Medir
Las actualizaciones de la página Medida están disponibles en vista previa pública.
La página Medir te ayuda a evaluar el rendimiento de un modelo en los documentos anotados antes de publicarlos. La página incluye:
- Una tabla de rendimiento de campo que muestra métricas de rendimiento clave por campo y grupo de campos.
- Soporte para comparar las diferencias de rendimiento entre las versiones del modelo, resaltando mejoras o regresiones.
- Visibilidad en la distribución de los tipos de error para cada campo de taxonomía.
- Capacidades de exportación de datos para análisis sin conexión personalizados.
Las siguientes secciones describen los componentes principales de Medir y explican cómo utilizarlos de forma efectiva al analizar el rendimiento del modelo.
Resumen del proyecto
La sección de resumen proporciona una vista rápida y de alto nivel de cómo se comporta tu versión actual de modelo en todo el proyecto. Puedes utilizarla para:
- Seleccionar la versión del modelo que quieres evaluar.
- Obtener una ojeada del rendimiento general utilizando Puntuación del proyecto y Tasa de error media de documentos.
- Detectar rápidamente si el rendimiento general del proyecto tiene tendencia al alza o a la baja al compararla con una versión anterior.

Puntuación del proyecto
La puntuación del proyecto resume el rendimiento general del modelo.
Por qué es útil
- Proporciona una forma única y coherente de realizar un seguimiento del progreso general a medida que iteras en la taxonomía, las instrucciones y las anotaciones.
- Te ayuda a determinar rápidamente si una versión de modelo generalmente mejora o empeora antes de analizar campos específicos.
Cómo se calcula
- La puntuación del proyecto se calcula como la media simple de las puntuaciones F1 en todos los campos de la taxonomía.
- La puntuación F1 es una métrica de rendimiento de modelo estándar que equilibra la precisión y el rendimiento, es decir, la media armónica de los dos.
- En un nivel alto:
- Respuestas de precisión: ¿con qué frecuencia eran correctos los valores predichos del modelo?
- Respuestas de recuperación: ¿cuántos de los datos anotados encontró correctamente el modelo?
La puntuación del proyecto es un promedio. Las regresiones o limitaciones específicas en el nivel de campo se pueden revisar con la tabla de rendimiento de campo.
Tasa de error media del documento
La Tasa de error media del documento es el promedio de las tasas de error para cada documento anotado en el proyecto.
Por qué es útil
La tasa de error media de documento proporciona un indicador rápido de cuán propensos son a error los documentos cuando la versión del modelo seleccionada los procesa, lo que ayuda a evaluar la preparación para publicar.
Cómo se calcula
El valor se calcula como el promedio simple de la tasa de error de cada documento completamente anotado en el proyecto.
Tabla de rendimiento de campo
La tabla de Rendimiento de campo es la forma principal de analizar el rendimiento del modelo en la página Medir. Muestra una fila por campo o grupo de campos, junto con las métricas de rendimiento y error calculadas en todos los documentos anotados del proyecto. La tabla no toma en cuenta los documentos no anotados y parcialmente anotados al calcular las métricas.
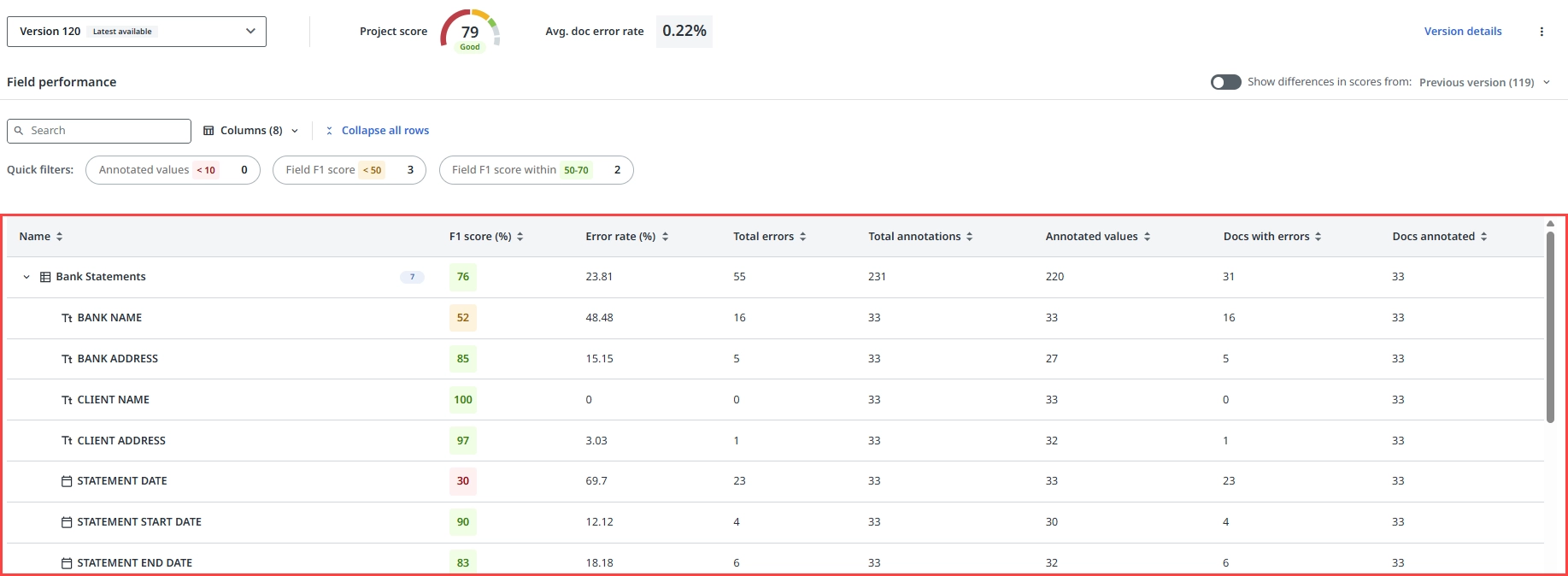
La tabla ayuda a responder preguntas como:
- ¿Qué campos limitan el rendimiento general del modelo?
- ¿Los errores se concentran en unos pocos campos o se propagan ampliamente?
- ¿Un cambio reciente de modelo mejoró o degradó los campos específicos?
La tabla de rendimiento de campo incluye varias categorías de métricas que te ayudan a analizar el rendimiento del modelo desde diferentes perspectivas. Cada categoría responde a una pregunta de diagnóstico específica sobre cómo se comporta tu modelo en los campos y documentos.
Estado de validación y resultados parciales Para reducir el tiempo de espera:
- Las métricas de rendimiento de campo se vuelven visibles una vez que la validación alcanza un umbral de finalización mínimo.
- Las advertencias indican cuando la validación aún está en progreso y que los resultados mostrados pueden cambiar.
Métricas de rendimiento
El propósito de las métricas de rendimiento es evaluar la calidad general de la extracción para cada campo o grupo de campos.
Las métricas de rendimiento se describen de la siguiente manera:
- Puntuación de F1: la media armónica de la precisión y la recuperación: F1 = 2 × (Precisión × Recuperación) / (Precisión + Recuperación).La puntuación F1 solo sigue siendo alta cuando tanto la precisión como la recuperación son altas. En la práctica, esto hace que F1 sea un indicador de calidad general sólido para las tareas de extracción en las que se busca evitar valores incorrectos y evitar valores perdidos.Por lo tanto, F1 es una métrica útil inicial para revisar y analizar los cambios de rendimiento de campo entre las versiones de modelo.
- Precisión: mide la frecuencia con la que los valores predichos son correctos: precisión = positivos verdaderos / (positivos verdaderos + falsos positivos). Los positivos verdaderos son las predicciones que coinciden con el valor anotado, excluyendo los valores anotados como faltantes.
- Recuperación: mide la frecuencia con la que el modelo encuentra un valor cuando existe: Recuperación = Verdaderos positivos / (Verdaderos positivos + Falsos negativos).Los falsos negativos son valores anotados que el modelo no predijo, excluyendo los valores anotados como faltantes.
- Tasa de error: errores totales / anotaciones totales. Los valores marcados como faltantes se incluyen en el recuento de errores y anotaciones.
- Tasa de error (excluyendo los faltantes): (Errores totales – predicciones adicionales) / Valores anotados. Se excluyen los valores anotados marcados como faltantes.
Predicciones y errores
El propósito de las métricas de predicciones y errores es comprender el volumen y la composición de los errores que contribuyen a un rendimiento deficiente.
Las métricas se describen de la siguiente manera:
- Errores totales: número total de errores para un campo en todas las clases de error: Errores totales = Predicciones incorrectas + Predicciones no cumplidas + Predicciones adicionales.
- Predicciones totales: número total de valores predichos para un campo: Predicciones totales = Valores correctos + Valores faltantes + Predicciones incorrectas.
- Predicciones incorrectas: número de predicciones en las que el valor extraído no coincide con la anotación. Excluye las predicciones y los valores anotados marcados como faltantes.
- Predicciones adicionales: número de valores predichos que el modelo no debería haber extraído, o no tenían una anotación correspondiente o una anotación marcada como faltante.
- Predicciones omitidas: número de valores anotados que el modelo no pudo extraer.
- Valores correctos: número de valores predichos que coinciden exactamente con la anotación.
- Faltantes correctos: número de instancias en las que el modelo predijo correctamente que falta un valor.
Anotaciones
El propósito de las métricas de anotación es proporcionar contexto de cuántos datos etiquetados admiten cada métrica y cuán fiables son las puntuaciones de rendimiento.
Las métricas se describen de la siguiente manera:
- Anotaciones totales: número total de anotaciones, incluidos los valores marcados como faltantes: anotaciones totales = Valores anotados + Valores anotados marcados como faltantes.
- Valores anotados: número total de valores de campo anotados, excluyendo los marcados como faltantes.
- Anotado como faltante: número total de veces que un campo se etiquetó explícitamente como faltante.
Métricas en el nivel de documento
El propósito de las métricas en el nivel de documento es comprender cómo se distribuyen los errores en los documentos en lugar de solo en las predicciones.
Las métricas se describen de la siguiente manera:
- Documentos con errores: número total de documentos en los que el campo tiene al menos un error.
- Documentos anotados: número total de documentos en los que el campo tiene al menos un valor de campo anotado.
- Porcentaje de documentos con errores: porcentaje de documentos anotados que contienen al menos un error para el campo: Documentos con errores / Documentos anotados.
Escenarios de ejemplo
Escenario 1: F1 baja + precisión baja, pero la recuperación es moderada o alta
Lo que observas
F1 es baja, la precisión es baja y la recuperación es moderada o alta.
Lo que suele significar
- El modelo extrae valores para un campo, pero hay más valores predichos de los que se espera encontrar.
- Causas raíz comunes:
- La instrucción de campo es demasiado amplia o ambigua. Por ejemplo, la instrucción de campo es capturar la cantidad, pero no especifica cuál cantidad.
- El documento tiene valores similares que se pueden confundir entre sí, por ejemplo, subtotal frente a total, envío frente a factura.
Qué hacer a continuación
Compara las predicciones incorrectas y las predicciones adicionales para identificar si la incidencia está vinculada a la extracción de un valor incorrecto (recuento de predicciones incorrectas distinto de cero) o si el valor no debería haberse extraído en absoluto (recuento de predicciones adicionales distinto de cero).
Ajusta las instrucciones de campo con desambiguadores, como etiquetas, palabras clave y restricciones de formato.
Escenario 2: predicciones no acertadas altas (la recuperación es baja), la precisión es moderada o alta.
Lo que observas
- La recuperación es baja y la precisión es moderada o alta (F1 suele ser baja o moderada).
- El número de predicciones omitidas es alto, a menudo más que incorrecto o adicionales.
Lo que suele significar
- El modelo falla al extraer valores que están presentes.
- Causas raíz comunes:
- La instrucción de campo es demasiado angosta, lo que significa ejemplos demasiado restringidos o requisitos de etiqueta demasiado específicos.
- El valor aparece en varios formatos, como fechas e ID, y la instrucción no cubre las variantes.
Qué hacer a continuación
- Usa Predicciones omitidas + Valores anotados para confirmar que se trata de un problema de recuperación, es decir, que los valores existen pero no se encontraron. Comprueba los valores anotados para confirmar que haya un número razonable de puntos de datos anotados para el campo y las predicciones omitidas para confirmar que el modelo luche por buscar valores en lugar de predecirlos incorrectamente.
- Expande las instrucciones para incluir variantes aceptables: etiquetas o sinónimos alternativos, varios patrones de formato, sugerencias de ubicación (por ejemplo, cerca de los detalles del solicitante o en la sección de prestatario).
Escenario 3: alta tasa de error pero pocos documentos con errores (errores concentrados en unos pocos documentos)
Lo que observas
- La tasa de error es alta o el Total de errores es alto.
- Los documentos con errores son bajos en relación con los documentos anotados.
- A menudo, un campo tiene un aspecto incorrecto pero solo falla en un pequeño subconjunto de documentos.
Lo que suele significar
- Los errores son impulsados por los documentos atípicos, no por el comportamiento sistémico del campo.
- Causas raíz comunes:
- Un documento o formato específico se comporta de forma diferente al resto.
- Incidencias de OCR o de calidad en un pequeño número de documentos, como escaneos borrosos, sesgados y superposiciones escritas a mano.
- El campo está presente en la mayoría de los documentos, pero tiene un formato inusual en unos pocos, por ejemplo, de varias líneas frente a de una sola línea.
Qué hacer a continuación
- Compara los documentos con errores y los documentos anotados y, opcionalmente, el porcentaje de los documentos con errores, para confirmar la concentración.
- Ordena los documentos por tasa de error en la página Crear e inspecciona los documentos con la tasa de error más alta para identificar si el campo tiene un rendimiento deficiente en un subconjunto específico.
Escenario 4: grandes oscilaciones de rendimiento entre versiones con pocas anotaciones
Lo que observas
- Grandes diferencias en la F1 o la tasa de error entre las versiones del modelo (hacia arriba o hacia abajo), pero los valores anotados son bajos, los documentos anotados son bajos o ambos.
Lo que suele significar
- Las métricas de campo aún no son estables debido al pequeño tamaño de la muestra.
- Causas raíz comunes:
- Demasiado pocos ejemplos: 1 a 2 documentos pueden cambiar significativamente las tasas.
- El campo rara vez está presente, es decir, muchos casos faltantes y pocos valores verdaderos.
- Un puñado de documentos difíciles dominan la métrica.
Qué hacer a continuación
- Comprueba Valores anotados, Documentos anotados y Anotados como faltantes para validar la baja cobertura.
- Trata las métricas como direccionales, no definitivas, hasta que aumente la cobertura.
- Añade más datos etiquetados específicamente para ese campo: da prioridad a los documentos en los que esté presente el campo e incluye un conjunto diverso de muestras o variantes.
- Usa las comparaciones de versión solo después de que la cobertura sea suficiente para reducir el ruido impulsado por la variabilidad.
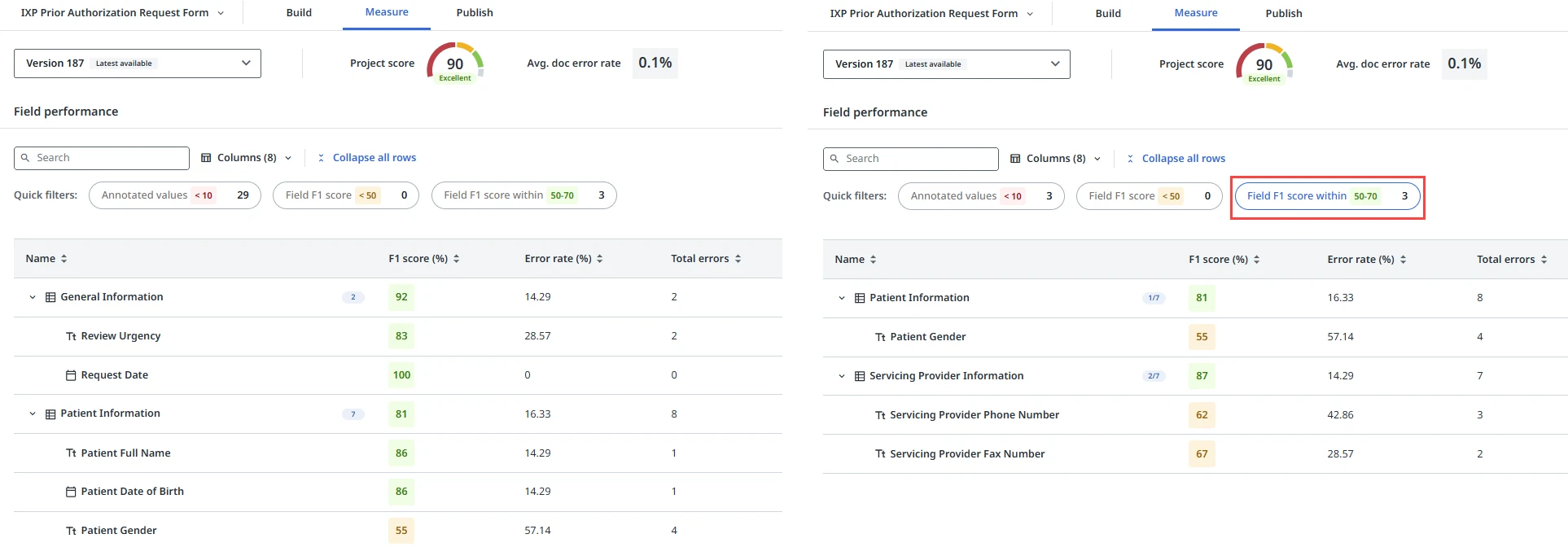
Filtrado y clasificación
Para filtrar las filas de la tabla, selecciona uno o varios de los filtros rápidos disponibles:
- Valores anotados <10
- Puntuación de campo F1 < 50
- Puntuación de campo F1 dentro de 50–70
Las siguientes imágenes representan un ejemplo de los resultados de la tabla de rendimiento de campo antes y después de aplicar un filtro rápido:
También puedes ordenar la tabla Rendimiento de campos por cualquier métrica de la tabla. Cuando se aplica una ordenación, los valores se ordenan dentro de su grupo de campos respectivo. Por ejemplo, ordenar la tabla por puntuación F1 ordena los campos dentro de cada grupo de campos entre sí:

Configuración de visibilidad
De forma predeterminada, Medir muestra diferencias en las métricas de rendimiento, por ejemplo, la puntuación F1 y la tasa de error.
Para ver las diferencias en todas las métricas, haz lo siguiente:
-
Habilita la alternancia Mostrar diferencias en las puntuaciones de: Versión.
-
Selecciona el desplegable Mostrar diferencias en las puntuaciones de: Versión.
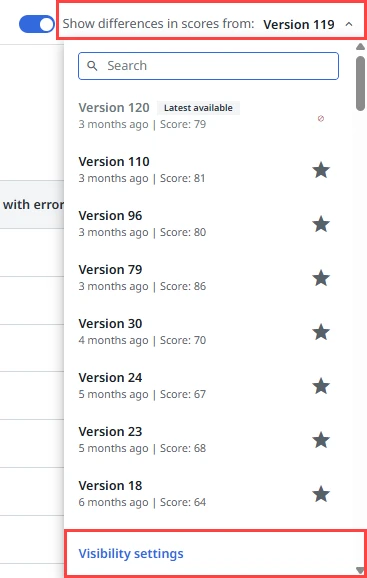
-
Selecciona Configuración de visibilidad.
-
En la ventana emergente Cambios en la versión - configuración de visibilidad, selecciona Todas las métricas.Las opciones disponibles son:
- Solo métricas de rendimiento: las métricas de rendimiento se determinan comparando las predicciones del modelo con las anotaciones, como la puntuación F1 y la tasa de error.
- Todas las métricas
- Mostrar cambios dentro de la variabilidad del modelo: de forma predeterminada, los cambios dentro de los rangos de variabilidad de la versión actual no se consideran significativos y se ocultan. Habilítalos para mostrarlos. Cuando se selecciona, la siguiente opción está disponible:
- Mostrar colores para todos los cambios: de forma predeterminada, los cambios dentro del intervalo de variabilidad aparecen en gris. Habilitar para colorear todos los cambios de verde o rojo.
-
Selecciona Guardar.
Versiones del modelo
Las versiones del modelo capturan el estado actual del proyecto en el momento en que se creó la versión. Puedes publicar versiones de modelo para guardarlas y utilizarlas en una automatización. Además, puedes marcar como favoritas las versiones en la página Medir para guardar sus estadísticas de rendimiento. Puedes comparar el rendimiento actual con las versiones anteriores para garantizar la mejora continua del rendimiento durante la iteración en las instrucciones.
Seleccionar una versión de modelo
Usa el menú desplegable Versión para elegir qué resultados de validación de una versión específica del modelo se muestran en toda la página Medir, como Rendimiento del campo, Rendimiento del documento y las métricas asociadas. Al cambiar la versión del modelo, todas las métricas de la página se actualizan para reflejar los resultados de la validación de la versión seleccionada.
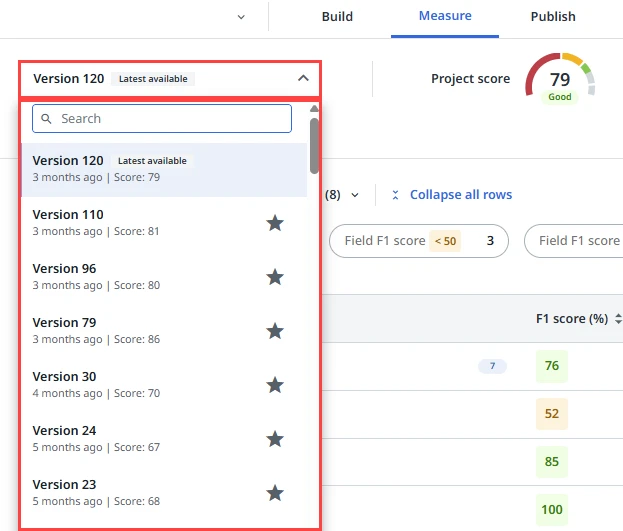
Comparar diferentes versiones de modelo utilizando diferencias de puntuación
Cuando hay varias versiones de modelo disponibles, la página Medir te permite comparar el modelo actual con una versión anterior. De esta manera, puedes comprender mejor el impacto de los cambios en las instrucciones de campo, los cambios en las anotaciones o las actualizaciones de configuración del modelo.
Cómo funciona
- Medir te permite ver las diferencias de puntuación de otra versión de modelo.
- Los cambios positivos o negativos resaltan mejoras o regresiones. De forma predeterminada, Medir realiza comparaciones con la versión anterior del modelo en relación con la versión del modelo creada más reciente.
Para comparar una versión diferente de modelo, selecciona una versión disponible utilizando el menú desplegable Mostrar diferencias en las puntuaciones de la versión.
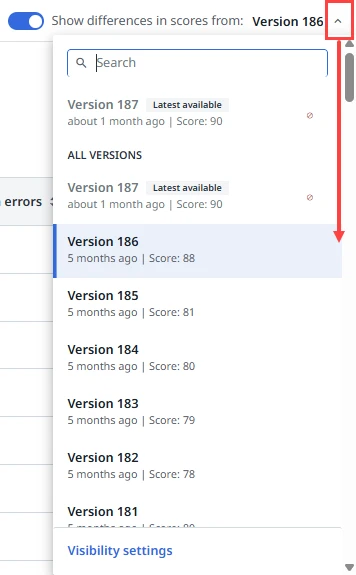
Comprender la variabilidad del modelo y el impacto en las diferencias de puntuación
Algunos modelos de Extracción y Procesamiento Inteligentes (IXP) no son deterministas, lo que significa que el conjunto de predicciones de un campo entre las versiones de modelo puede variar ligeramente incluso cuando las instrucciones de ese campo no cambian.
La página Medir te permite tener en cuenta la variabilidad del modelo durante el análisis de rendimiento. Esto te ayuda a:
- Comprender si un cambio de rendimiento es significativo.
- Evitar sobreinterpretar pequeñas fluctuaciones métricas.
De manera predeterminada:
- Las diferencias de puntuación que caen dentro del intervalo de variabilidad de una métrica están ocultas al comparar dos versiones de modelo.
- Puedes seleccionar para mostrar todos las diferencias de puntuación o solo las diferencias que sean mayores o iguales a la variabilidad de una métrica.
Estos valores predeterminados garantizan que la atención se centre en los cambios significativos en el rendimiento del modelo, y no en el ruido.
Para mostrar las diferencias entre las versiones del modelo independientemente de la variabilidad del modelo, haz lo siguiente:
- Habilita la alternancia Mostrar diferencias en las puntuaciones de: Versión.
- Selecciona el desplegable Mostrar diferencias en las puntuaciones de: Versión.
- Selecciona Configuración de visibilidad.
- En la ventana emergente, selecciona Mostrar cambios dentro de la variabilidad del modelo. Las opciones disponibles son:
- Solo métricas de rendimiento: las métricas de rendimiento se determinan comparando las predicciones del modelo con las anotaciones, como la puntuación F1 y la tasa de error.
- Todas las métricas
- Mostrar cambios dentro de la variabilidad del modelo: de forma predeterminada, los cambios dentro de los rangos de variabilidad de la versión actual no se consideran significativos y se ocultan. Habilítalos para mostrarlos. Cuando se selecciona, la siguiente opción está disponible:
- Mostrar colores para todos los cambios: de forma predeterminada, los cambios dentro del intervalo de variabilidad aparecen en gris. Habilitar para colorear todos los cambios de verde o rojo.
- Opcionalmente, selecciona Mostrar colores para todas las diferencias si quieres que todas las diferencias de puntuación aparezcan en verde o rojo. De forma predeterminada, las diferencias dentro del intervalo de variabilidad se muestran en gris.
- Selecciona Guardar.
Destacar una versión del modelo
Cada vez que se realizan cambios en la taxonomía, incluidas las instrucciones, o en la configuración del modelo, se crea una nueva versión del modelo. La versión más reciente del modelo siempre está disponible, pero también puedes marcar, es decir, bloquear en su lugar, una versión específica del modelo para mostrar siempre las estadísticas de rendimiento en el panel.
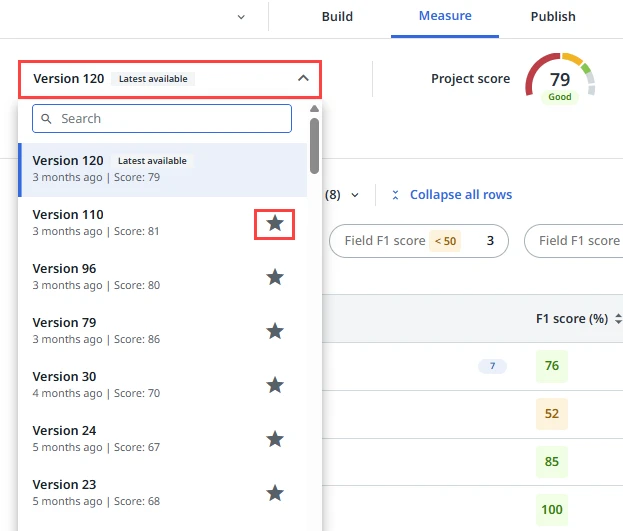
Para destacar una versión del modelo, procede de la siguiente manera:
- Expande el menú desplegable Versión del modelo para ver la lista con todas las versiones disponibles.
- Selecciona el icono de estrella junto a la versión del modelo que quieres que se muestre siempre en la parte superior de la lista y en el panel.
Al destacar una versión del modelo no se guarda la versión del modelo en sí, solo las estadísticas de rendimiento. Para guardar una versión del modelo, debe publicarse en la pestaña Publicar .
Exportar datos de Medir
Puedes exportar datos de la página Medir para:
- Análisis sin conexión.
- Filtrado personalizado.
- Compartir resultados con las partes interesadas.
Las exportaciones incluyen predicciones en el nivel de campo, anotaciones y métricas de rendimiento visibles en la página Medir.
Para exportar datos, haz lo siguiente:
- Ve a la página Medir.
- Selecciona los tres puntos verticales.
- Selecciona Exportar como archivo de Excel.

- Evaluación del rendimiento del modelo en Crear
- Evaluar el rendimiento del modelo en Medir
- Resumen del proyecto
- Tabla de rendimiento de campo
- Versiones del modelo
- Seleccionar una versión de modelo
- Comparar diferentes versiones de modelo utilizando diferencias de puntuación
- Destacar una versión del modelo
- Exportar datos de Medir